
Deep learning is a powerful machine learning technique. These are widely used in
- Natural Language Processing (NLP)
- image/speech recognition
- robotics
- and many other artificial intelligence projects
What is Deep Learning?
A model which consists of more than three layers in a neural network model is a deep learning model. More than three layers means one input layer, one output layer which are must, more than one hidden layer.
In other words, neural network with more than one hidden layers (which is same as more than three layers) is a deep learning model (for more on this, click here and here).
Advantages
- Powerful technique which can be applied in various fields
- In many cases, outperforms all other classical models
- Captures interaction among input variables, non-linear complex relationship between input variables and output variables
- No assumptions about input variables and error terms
(For more on this).
Disadvantages
- Biggest disadvantage is that it is a ‘black-box’ model: interpretation is not possible
- Requires high quality huge data
(For more on this).
Concepts
- Forward propagation
- Weights
- Layers
- Activation functions
- Backpropagation
In this video, neural network structure has been explained very clearly. I recommend that you watch these 7 part videos.
I used the same notations for representation.
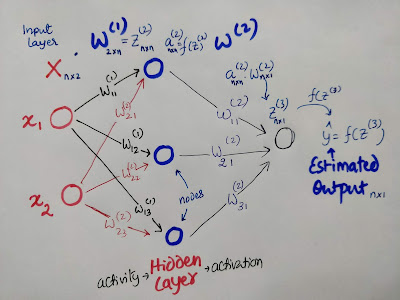
Neural Network Structure
In the above notation: There are two independent variables (x1and x2). If we represent these data in a matrix form (X), then order of X will be of n×2.
W(1) represents the weights before the first layer. Weights are model parameters, (not hyperparemeters unlike number of nodes or number of layers). At each node, the product of input values and weights are summed. In matrix notation, Z(2)= X.(1). Z(2) represents matrix comprising of sum of products. These are also referred to as the activity.
The activity passes through the activation function at each node. Depending on the activation function used, the matrix Z(2) are transformed into the matrix a(2). That is a(2) = f(Z(2)).
Mostly, non-linear activation functions are used:
- Because non-linear activation functions capture non-linear, complex relationships between inputs and output.
- And, if we use linear activation function, then even if we use multiple hidden layers, effectively it will be same as using a single hidden layer.
W(2) represents the weights after the first layer. The same process is repeated here too. Finally we get Z(3) which is the product of matrices a(2) and W(2). Dimension of the resulting matrix will be n×1.
Again this matrix Z(3) will be transformed using activation function to get the final predicted output which will also be of the order n×1. That is ŷ = f(Z(3)). Since there are n observations, there will be n predicted outputs (hence the order: n×1).
Exercise
Can you find out the final output values for the following example?
In the input nodes, I have written the values of the first observation i.e. x1=1 and x2= 2. Compute the product of the input values and the weights and sum these values at each node. Use identity activation function (i.e. no transformations).
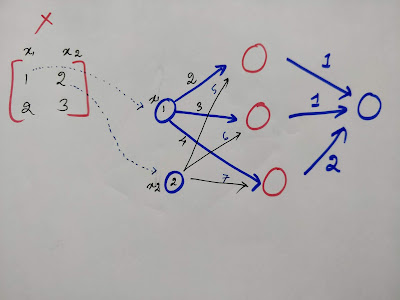
Solution:
Using Excel matrix multiplication function, I have calculated the predicted output value matrix (63 and 101). Since the activation function is identity activation function (which is same as no activation function), matrix Z(2) and a(2) are same.
- Forward propagation : to predict the output in order to calculate error.
- Weights : indicate the strength of relationship between nodes. These are model parameters.
- Layers : how many hidden layers to use and number of nodes are left to the judgement of the data scientist.
- Activation functions : Rectified Linear Unit (ReLU) is the commonly used activation function.
- Backpropagation : to optimize the weights.
Forward Propagation:
Main purpose here is to get the prediction/output so that we can calculate the error as we already know the real value of the output in training set.
Backpropagation:
To estimate the gradient (slope of the loss function with respect to weights) in order to optimize the weights which minimize loss function.
Summary
In this post, we have explored the basic concepts and structure of deep learning models.
References:
- Must watch videos.
- If you want to learn all deep learning techniques with beautiful representations read thisand watch this.
- Play with neural networks on your own.
- Very good summary of neural networks and concepts.
- https://www.bogotobogo.com/python/scikit-learn/Artificial-Neural-Network-ANN-1-Introduction.php
- http://www.mlopt.com/?tag=forward-propagation
- https://www.analyticsvidhya.com/blog/2018/10/introduction-neural-networks-deep-learning/