
In this post, let us explore:
- Random Forest
- When to use
- Advantages
- Disadvantages
- Hyperparameters
- Examples
Random Forest
Forest is a collection of trees. Random forest is a collection of decision trees. It is a bagging technique. Further, in random forests, feature bagging is also done. Not all features are used while splitting the node. Among the available features, the best split is considered. In ExtraTrees (which is even more randomized), even splitting is randomized.
When to use
Random forest can be used for both classification and regression tasks. If the single decision tree is over-fitting the data, then random forest will help in reducing the over-fit and in improving the accuracy.
Advantages
- Avoids over-fitting
- Training the individual trees can be parallelized (since in bagging, estimation is parallel)
- Popular
Disadvantages
- Black box model: Not interpretable
- Performance is not good when there is class imbalance
Hyperparameters
- Bootstrapping
In sci-kit learn, when random forest model is estimated, each tree is built on a sub-sample which is equal to the size of original dataset. Sub-samples are drawn with replacement if bootstrapping is used.
E.g.: If the total number of observations is five, then the sub-sample size is also five but samples are drawn with replacement.
If number of n_estimators=10, then there will be 10 such sub-samples. Orignal data: [1,2,3,4,5]
Sub-samples with bootstrap =True: [1,1,3,4,5], [4,5,2,2,1], [3,3,2,3,5]……10 such sub-samples
One an average, each bootstrap sample will contain 0.632 of observations, rest 0.368 of observations are not selected (out of bag). In the above example, 2 was not selected in the first bootstrap sample.
Using these remaining 36.8% of observations, we can calculate the accuracy of the model (OOB score).
Sub-samples if bootstrap=False: [1,2,3,4,5] itself will be the sub-sample. That means original set will be the sub-sample when bootstrap is set to false.
To know more about bootstrapping, jacknife, randomization test (permutation) and other resampling methods, I recommend you to go through this thread particularly the pictorial representation at the end. By default bootstrapping is set to false in ExtraTrees.
- n_estimators
Number of decision trees in the random forest model. Default is 10. More uncorrelated the tree, the better it is. If individual trees do no commit same error, then averaging them gives better accuracy. But more number of trees does not necessarily mean better because of law of diminishing returns operating here too! Because of cost of computation and not much increase in accuracy after certain number of trees, we should be careful in choosing the number of estimators (link).
- max_features
In classification problem, default is square root of number of features. In regression problems default is number of features.
To know more, refer to scikit-learn manual on RandomForestClassifier and RandomForestRegressor.
Example
I have used the same data that was used in demonstrating decision tree (Titanic dataset).In random forest, there is no need to use cross-validation, Out-of-Bag (OOB) score is enough. But just to compare, I have calculated OOB score, CV-accuracy and test accuracy.The base estimator is decision tree with n_estimators=50, max_depth=None, min_samples_split=2, oob_score=True.
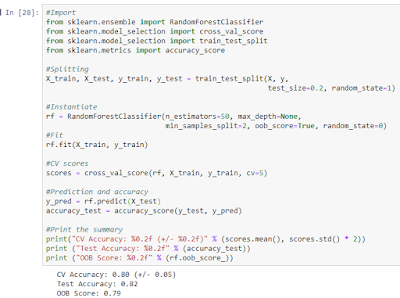
OOB score (0.79) and cross validated accuracy (0.80) values are close.
- Feature importance
As name suggests, feature importance gives the importance of the features in predicting the dependent variable. In scikit-learn, mean decrease in impurity (MDI) measure is used to compute feature importance (link).
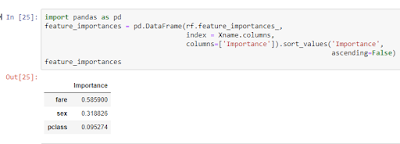
I have stored the feature names in seperate dataframe Xname because numpy array removes the column names. Using barplot, we can visualize.
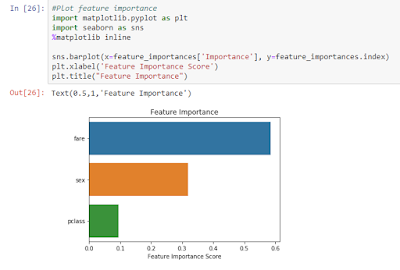
You may refer this datacamp article and this article to know more about this.
Further, if you want to see the structure of individual trees of the random forest, use rf.estimators_ attribute.
Summary
In this post we have explored:
- Random Forest
- When to use
- Advantages
- Disadvantages
- Examples
If you have any questions or suggestions, do share. I will be happy to interact.