
Occam's Razor, Bias-Variance Tradeoff, No Free Lunch Theorem and The Curse of Dimensionality
In this post, let us discuss some of the basic concepts/theorems used in Machine Learning:
- Occam’s Razor (Law of Parsimony)
- What is Bias-variance Tradeoff
- No Free Lunch Theorem
- The curse of dimensionality
Occam's Razor (Law of Parsimony)
William of Ockham was a 13th century philosopher, he stated, “among competing hypotheses, the one with the fewest assumptions should be selected”.
This principle is useful in machine learning as well. Given equal performance, we should always choose a simpler model.
Bias-variance Tradeoff
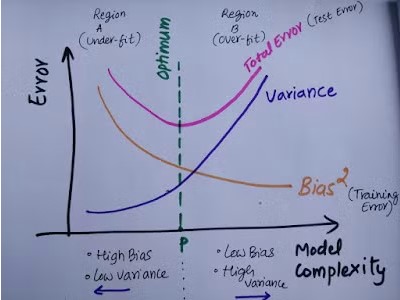
The following picture shows the relationship between model complexity and error. Model complexity doesn’t necessarily mean prediction would be more accurate.
Generalization error (Total error) can be decomposed into square of bias, variance and irreducible error. Bias means the difference between predicted value and the actual value. Variance refers to lack of consistency. And irreducible error can’t be predicted.
With increase in model complexity, bias decreases but variance starts to increase. Hence after the point P, total error starts to increase.
The region A, is the region of under-fitting. Here bias is higher while the variance is lower. In this region, model is too simple to capture the relationship. Solution is to increase the complexity till point P.
In region B, due to over-fitting, the total error is increasing. Even though, bias is lower, higher variance is causing the generalization error to increase. Model is too complex and it is almost byhearting the training data but it fails on test or unseen data. The challenge is to reach the point P, where model is of optimal complexity and generalization error is lowest.
No Free Lunch Theorem (NFLT)
According to Wolpert and Macready, “any two optimization algorithms are equivalent when their performance is averaged across all possible problems”.
This means, there is no single model which outperforms all other models in all situations. In other words, we have to select a model which is suitable for the given data.
The curse of dimensionality
With increase in dimensions (features), the amount of data needed to obtain a statistically reliable result, increases exponentially with the dimensionality.
If you have any questions or suggestions, do share. I will happy to respond.